While Python is an all-purpose general programming language, its success has mostly been in the arena of data analysis (including by academics), thanks to its compact, abstracted libraries that simplify complex underlying processes. When it comes to data analysis, advanced LLMs are particularly capable in Python as well as R and any other ‘scripting’ language which exists as text and therefore likely to have been in the LLM's training data.
With a paid Chat GPT license, there are two options to support quantitative data analysis. The first – and strongly recommended for any non-trivial case - is not to share any data but instead give it all the information it needs to provide you with the code for you to do the analysis yourself. The second is to use the built-in ‘Code Interpreter’ (officially the name changed to ‘Advanced Data Analysis’ in 2023 but most people still refer to it as Code Interpreter), which allows you to upload data files and GPT can write, test, debug and run code, and output files, in its own hosted environment. Code Interpreter is remarkably effective, particularly when you see it showing its working to plan, inspect, clean up (e.g. deal with missing values), analyse, fix its own errors and correct before sharing its result with you. But unless you have a Chat GPT Team or Enterprise license (and even then you should never include any personally identifiable or sensitive information), it’s a terrible idea (it could also break a grant funder’s rules) to upload data relating to a live research project since it could be stored by Open AI and future LLMs will be trained on it. But testing it out on publicly available datasets such as those available on Kaggle which are explicitly shared for public analysis is a great idea to see it in action. Let’s see an example of this using the QS World University Rankings 2023 data:
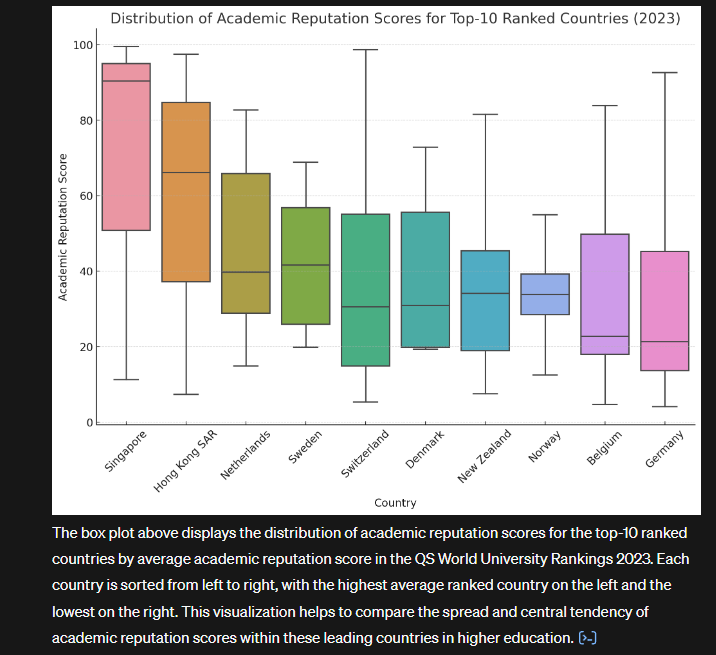
Generally speaking, the simpler the task, the less detail needed in the prompt. Here’s an example of a more complex analysis request on the same dataset. Ideally the user would put in some effort to explain that some of the data is messy with mixed data types in columns that would prevent certain calculations from being possible. But even here you can see GPT4 responding, understanding and correcting its errors before producing the final result without requiring user intervention:

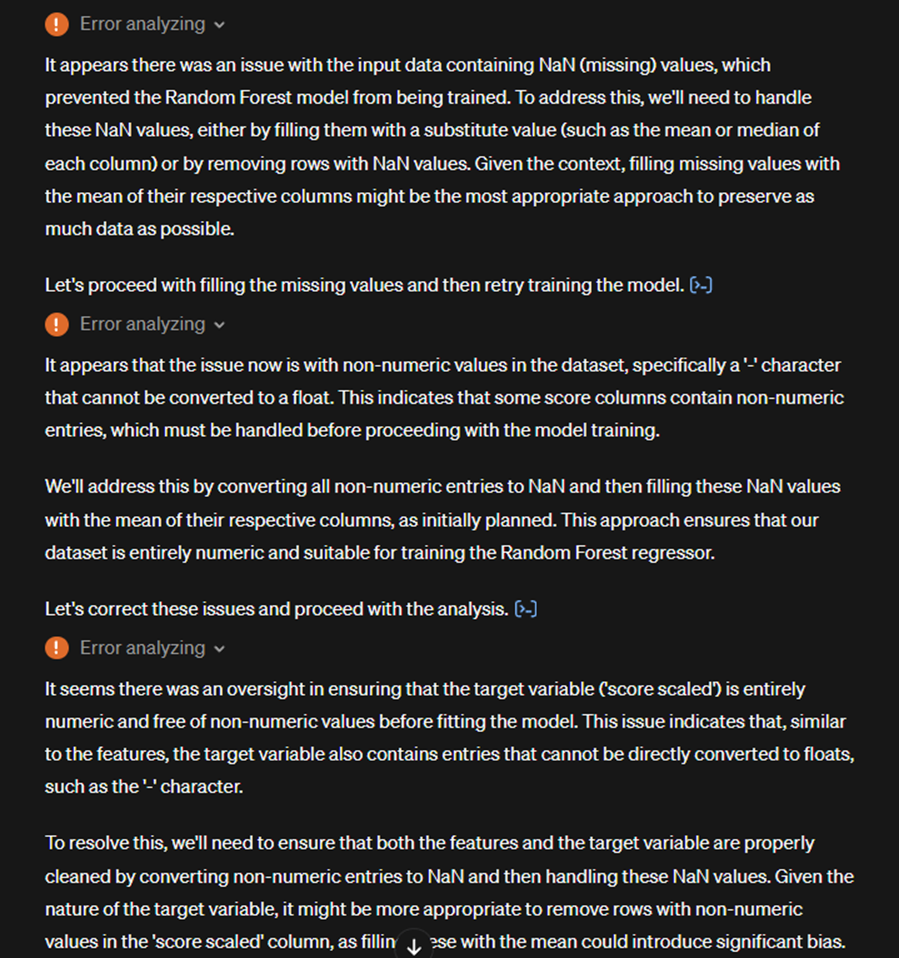

For the most part, Code Interpreter is really only viable for initial exploration or experimentation of non-confidential data. Even disregarding the huge data breach risks, you typically always want full control over any analysis, and while you can copy and paste Code Interpreter’s own output, it will rarely be in the format you use especially as you continue with analysis. For its own benefit when continuing a dialogue it often generates unwieldly column names, e.g. ‘profit_now_formatted_as_percentage_change’ if you asked it to change the format of a column from a previous iteration, making it a mess to deal with later.
Far better is to give it descriptions of your data including table names, column names, types and some example (anonymised, if relevant) rows and ask it to provide draft code which you can then adapt, re-name and test locally. This has the added benefit that you can share your own version of the code with the GPT4o and ask it to make any additions using your own style and naming conventions.
Here’s an example using a dataset which is far too large (2GB) to upload to the Chat GPT Interface: the 2024 LinkedIn Jobs and Skills dataset which contains over a million rows. This time it’s just being given the fundamental information it needs to provide draft code that the user can work on themselves:

Here's the code it provided which worked first time (even if it doesn't, continuing the dialogue to debug and ask for an updated corrected version doesn't take long):
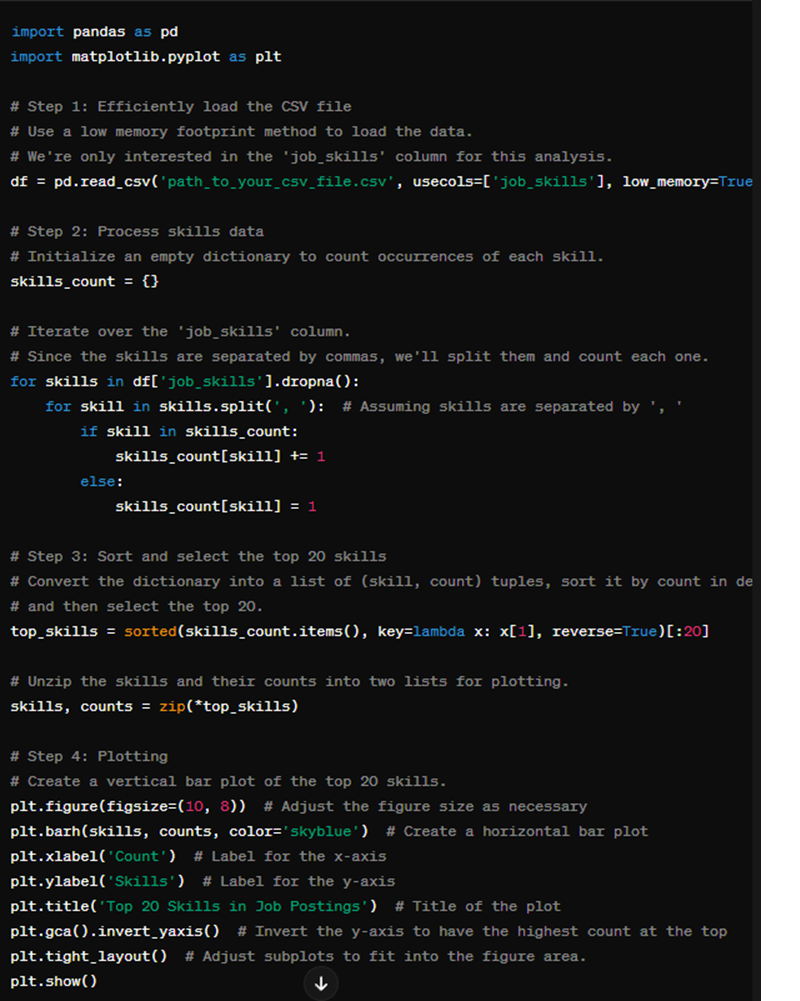
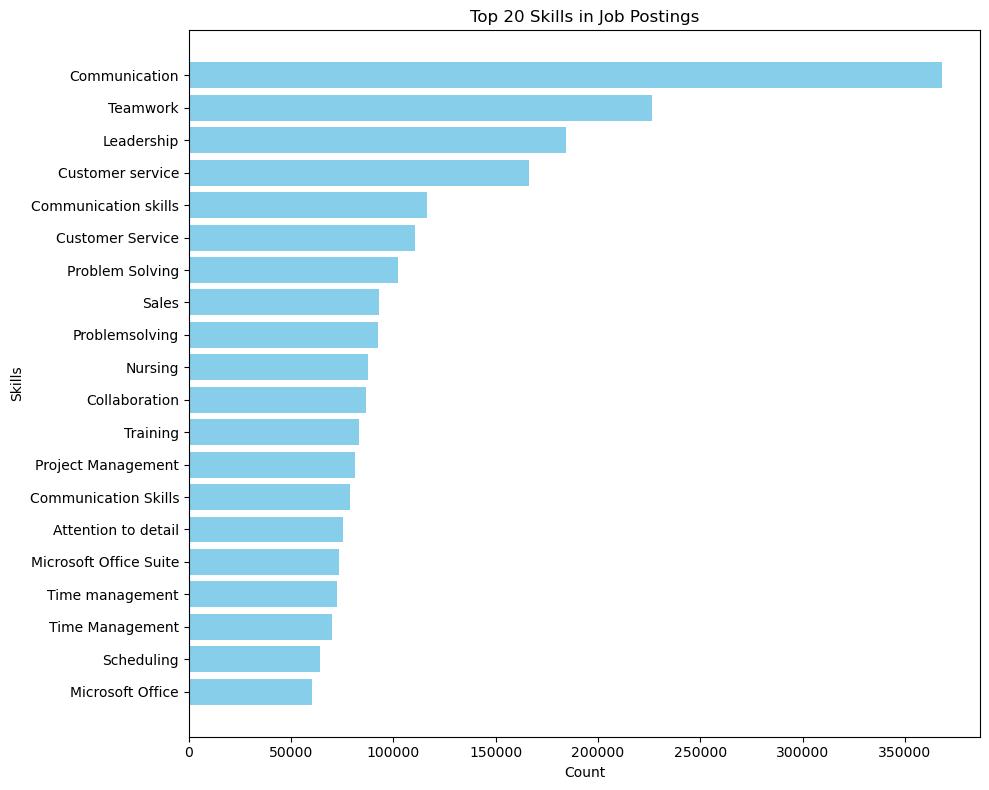
As a task becomes more complex, and especially in cases where the data requires pre-processing or cleaning, the more effort you put in to explain any issues in advance the less time you’ll spend asking the LLM to help debug errors. As with most use cases, the more you already know about a task, the clearer you can explain it so that the LLM can enhance your productivity. If you know nothing about data in the first place you will have a rough time because GPT4 will have to make assumptions and you won’t know enough to be able to correct them if they’re not applicable. That said, with some engagement you can have GPT4 act as a continually available, non-judgemental tutor to help you understand these concepts in a personalised way as you go along.