The concept of context length is vital and many of the setbacks people face are due to LLMs not being capable of handling more than a set number of tokens in memory. The token context length is a moving window of what can be considered ‘total conversational memory’. Let’s say an LLM can handle 2,000 words total. Your prompt contains all the important instructions and is around 500 words. After a few messages exchanged in the chat interface, the chat is now 2,100 words. The first 100 words of your prompt simply no longer exist, the model can only continue based on the last 2,000 words. This can have negligible impact or it can be devastating on subsequent output quality, depending on what was in those first 100 words.
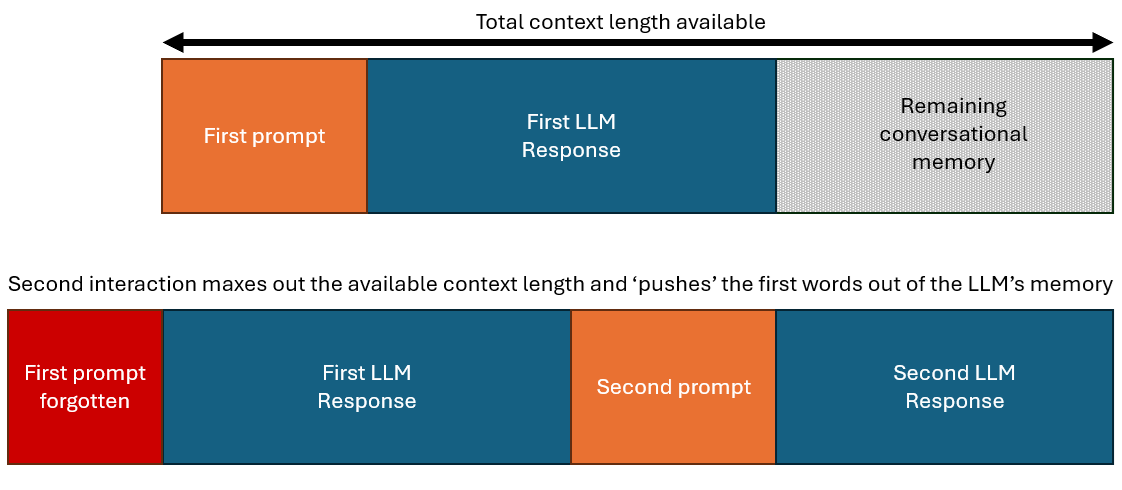
This is a problem because Chat GPT for instance never alerts the user that the maximum number of tokens are in use, which can lead to confusion and frustration as to why your original instructions are no longer being followed. Claude's interface actively prevents a conversation from reaching the context limit, which can be frustrating for some but helps mitigate the confusion from lost earlier information.
Regardless of stated context lengths for a given model (GPT o1 pro mode permits 200k as do Anthropic's models, and Gemini has 1M and 2M context windows), in practice they all struggle with longer texts and are more prone to misunderstanding or 'hallucinating'. Problems are inevitable given the ambiguity of prompts, implied context that the user might think is obvious but the LLM isn’t aware of, and the vast scale of text at which to direct its focus - often on multiple different parts (known as 'multi-hop reasoning') - when responding.
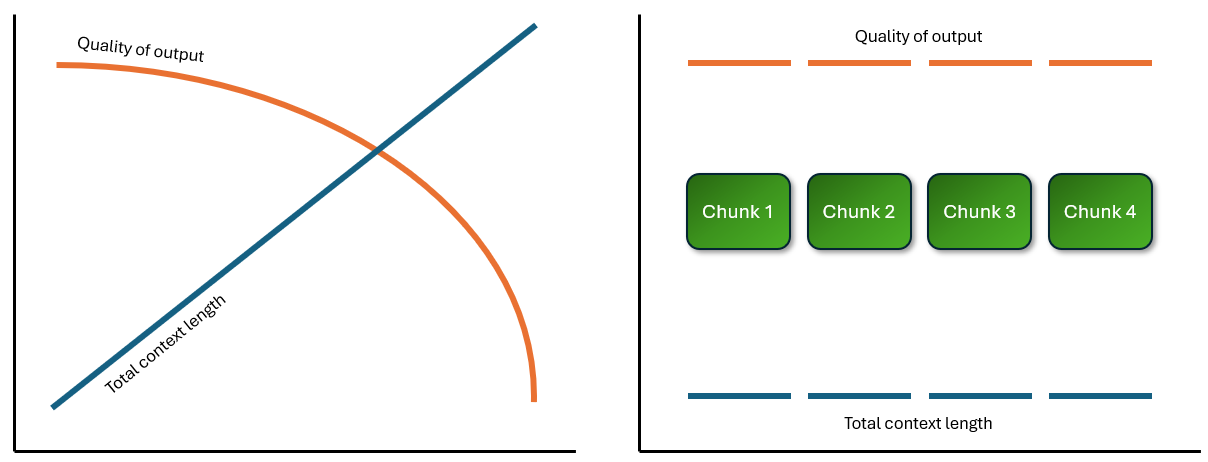
The more you can break up tasks so that the total scale of information needed is a few thousand words, the better quality the results. The diagram below illustrates the value of splitting tasks into chunks to maintain higher quality:
In April 2024, papers published associated with Google and Meta independently claimed to have developed novel methods that could theoretically permit ‘unlimited’ context windows for LLMs. The papers used much smaller models so how effective these can be with established LLMs that exhibit advanced reasoning remains to be seen. But if a future generative AI model is able to intelligently and accurately handle tens of millions of tokens and output the same quality as the current best LLMs can with a few thousand words, it could transform not only academia but knowledge work generally. Tens of millions of tokens could cover several years' worth of emails and local documents or an entire course reading list. Until any model emerges that has that capability though, breaking up generative AI tasks into smaller mangable chunks produces much better results and is the recommended approach.